ChowJS: an AOT JavaScript engine for game consoles
Hello, and welcome to the MP2 Games tech blog! I’m Mathias, and this is the first entry in what will hopefully become a long series of technical deep dives into some of the work we do at MP2.
Recently, we have been working on getting a large JavaScript game to run on game consoles. To make that happen, we made use of ChowJS, our ahead-of-time JavaScript compiler and runtime which can target game consoles.
Note: We will assume some knowledge about gamedev, JS and compilers to keep things short.
Note 2: ChowJS is not directly related to Chowdren, which is our compiler and runtime for Clickteam Fusion and Construct 3.
Intro
JavaScript is a very popular programming language, and for good reason. It’s easy to build JS applications quickly, the ecosystem is amazing, and there is great support for JS on platforms like PC and mobile through browsers or runtimes like Node.
The story is a bit different if you are building a serious multi-platform game in JS. In particular, the path to getting JS to run on game consoles has been problematic for a long time. Why is that?
JavaScript with JIT
To execute JS programs, you need to make use of a JS engine. Some popular choices today include
- V8 (Node.js, Chrome)
- SpiderMonkey (Firefox)
- JavaScriptCore (Safari)
Common for all of the major JS engines is that they make use of just-in-time (JIT) compilation. Briefly, this means that code is optimized and compiled to machine code at runtime, and this turns out to be very important.
V8 with JIT disabled can be 5x or even 17x slower than V8 with JIT enabled, which is a dramatic difference. To put this into perspective, let’s say your game is spending 8ms to complete each frame under standard V8. Assuming a 5x slowdown when disabling the JIT, this would result in a frame time of 40ms, running well below any 60 FPS target.
With game consoles often running on constrained hardware, a JIT is then critical to achieve acceptable frame times. However, most consoles don’t allow user applications to create executable code at runtime, effectively removing the possibility of using a JIT.
JavaScript without JIT
To run JS on consoles, you are then left with 3 options:
- Use a JS engine in interpreted mode.
- Compile and optimize your code offline, i.e. ahead-of-time (AOT) compilation.
- Manually rewrite your source project in another language, like C++.
For performance reasons, using an interpreter turned out to be infeasible for us. In our case, we also have the following constraints:
- The game is still being changed regularly.
- The game is huge and not written in a uniform way, with many different styles and paradigms being used.
- The game uses many dynamic JavaScript features such as monkeypatching
and
eval.
For that reason, rewriting the entire project was out of the question, and that leaves us with AOT compilation. We are now happy to present our solution to this: a JavaScript engine called ChowJS.
Sidenote about related work: As far as we are aware, Hermes is the only production-quality AOT compiler for JS. Unfortunately, it only compiles to bytecode and not machine code, and does not support all the features we need. Some non-public compilers have also been made for specific games, like Rob’s JavaScript → Haxe compiler. Rob’s compiler was made to support the specific JS subset used by CrossCode, and I don’t think the same approach would have worked for us. Lastly, Fastly recently announced this, but it seems like it only implements a JS interpreter in Wasm for now.
ChowJS
ChowJS is a fast AOT engine for JavaScript. It has the following features:
- Support for modern JavaScript including ES2020.
- Runs on PC, mobile and console platforms (same platform backends as Chowdren).
- Provides a subset of the NW.js runtime environment.
- Uses an AOT compiler to generate fast machine code using an SSA IR.
- Highly configurable optimizations.
- Implements inline caching for fast property lookups.
- Uses a reference counting GC.
ChowJS is heavily based on QuickJS, which we found to be an excellent JavaScript engine to hack on. In particular, we borrow the bytecode, interpreter and the ECMAScript support from QuickJS.
How does it work?
One important observation is that most JavaScript programs exhibit fairly static behavior after their startup phase, and this is also why JITs work. After startup, prototypes are very unlikely to change, most globals don’t change, and so on. In an AOT context, we can still capitalize on this.
Consider the following program:
function Test()
{
};
Test.prototype.foo = function()
{
console.log("hello world!");
};
Test.prototype.bar = function()
{
this.foo();
};
Here is an overview of how ChowJS would compile this program:
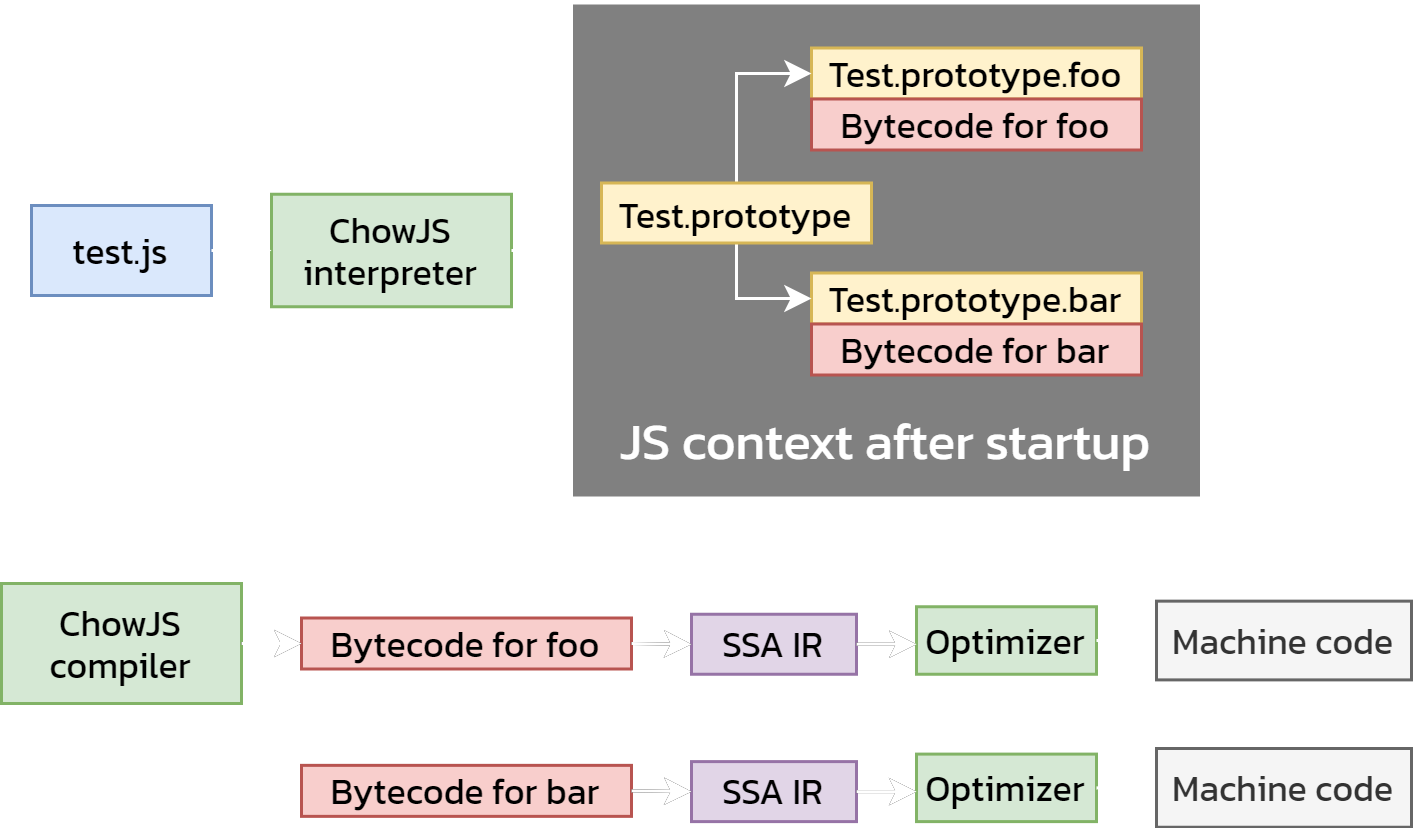
To elaborate, here is what is happening:
- We run the program in the ChowJS interpreter until the startup phase has completed. Methods have been compiled to bytecode at this point.
- For each method, we
- transform the bytecode of the method to our IR.
- perform several passes and optimizations over the IR.
- translate the IR to C and compile it to machine code.
For AOT compilation, it is critical that we have access to
the startup JS context, since this makes user objects, prototypes and methods
available to us at compile time and makes optimization a lot more straightforward.
For example, when compiling bar, we can show that foo is part of the same
prototype as bar, making the this.foo() call an excellent candidate
for function inlining.
We will now do a brief review of important parts of the compiler. If you don’t have a keen interest in compilers, feel free to skip to the Performance section.
Bytecode
Consider the following function:
function printParity(x) {
var s;
if (x % 2 == 0)
s = "even";
else
s = "odd";
print("Your number is " + s);
};
The bytecode generated for this function is as follows:
[000] get_arg <ArgRef: 'x'>
[001] push_i32 2
[002] mod
[003] push_i32 0
[004] eq
[005] if_false <Label: 15>
[007] push_atom_value <AtomRef: 'even'>
[012] put_loc <VarRef: 's'>
[013] goto <Label: 21>
[015] push_atom_value <AtomRef: 'odd'>
[020] put_loc <VarRef: 's'>
[021] get_var <AtomRef: 'print'>
[026] push_atom_value <AtomRef: 'Your number is '>
[031] get_loc <VarRef: 's'>
[032] add
[033] call 1
[034] return_undef
The bytecode is stack-based. For example
get_arg <ArgRef: 'x'>will push thexargument onto the stackpush_i32 2will push2onto the stack.modwill pop thexand2values from the stack and push the result ofx % 2.
To handle control flow, instructions like return_def, call and if_false
are used. For example, if_false will jump to the given
address label if the first value popped from the stack is false, while
goto will perform an unconditional jump.
The bytecode is designed to be executed by an interpreter, but aside from simple peephole optimizations, it is difficult to manipulate. For that reason, we transform it into an intermediate representation (IR) that is much more amenable to analysis and optimization.
SSA IR
ChowJS uses an IR in static single assignment
(SSA) form
with a control-flow graph (CFG) to represent control flow.
In SSA form, each variable is assigned exactly once, and we use
ϕ (phi) functions to merge values from different basic blocks.
There are several ways to go from a stack-based bytecode to an SSA IR like ours, but here are some valuable references:
The initial and unoptimized IR for the printParity function is as follows:
BB0:
%0 = get_arg 0
%1 = undefined
%2 = push_i32 2
%3 = mod %0, %2
%4 = push_i32 0
%5 = eq %3, %4
if_false <BlockRef: BB2> <BlockRef: BB1> %5
BB1:
%6 = push_atom_value <AtomRef: 'even'>
goto <BlockRef: BB3>
BB2:
%7 = push_atom_value <AtomRef: 'odd'>
goto <BlockRef: BB3>
BB3:
%8 = phi <BlockRef: BB2> <BlockRef: BB1> %7, %6
%9 = get_var <AtomRef: 'print'>
%10 = push_atom_value <AtomRef: 'Your number is '>
%11 = add %10, %8
%12 = call 1 %9, %11
return_undef
Instructions now have explicit output and input values, and it is simple to
infer relationships between them. Also note that %8 makes use of the
phi instruction to select either %7 or %6 depending on which basic block
we came from.
IR passes and optimization
We run through a number of passes to transform the IR:
CallApplySimplification → CacheValuePass → ExplicitToObject →
InlinePass → DCE → CriticalEdgeSplitting → Typer → Lowering
Here is what the IR for printParity looks like after all passes have run,
but before going out of SSA form:
Type info:
%0: Unknown (no_rc: true)
%2: int (no_rc: true)
%3: float (no_rc: true)
%4: int (no_rc: true)
%5: bool (no_rc: true)
%6: str (no_rc: true)
%7: str (no_rc: true)
%8: str (no_rc: true)
%9: ObjectRef (no_rc: true)
%10: str (no_rc: true)
%11: str (no_rc: false)
%12: Unknown (no_rc: false)
BB0:
%0 = get_arg 0
%2 = push_i32 2
%3 = mod %0, %2
%4 = push_i32 0
%5 = eq %3, %4
if_false <BlockRef: BB2> <BlockRef: BB1> %5
BB1:
%6 = push_atom_value <AtomRef: 'even'>
goto <BlockRef: BB3>
BB2:
%7 = push_atom_value <AtomRef: 'odd'>
goto <BlockRef: BB3>
BB3:
%8 = phi <BlockRef: BB2> <BlockRef: BB1> %7, %6
%9 = push_val <ObjectRef: 'print'>
%10 = push_atom_value <AtomRef: 'Your number is '>
%11 = add %10, %8
%12 = call 1 %9, %11
kill %11, %12
return_undef
There are several things to note about the above:
- At this stage, we handle lifetimes of values explicitly.
If a value needs to be reference counted, we
increment its reference count when it is created, and we decrement its
count using the
killinstruction. - The
Typerinferred the types of almost all values, and also figured out what values need to be reference counted. push_valis an instruction that yields a value known at compile time. In the final machine code, this requires no property lookups and the operation is very fast. In this case, we were able to optimize away the property lookup needed forprinton the global object.%1 = undefinedwas removed as dead code.
Let’s take a closer look at some of the important passes.
CacheValuePass
CacheValuePass plays an important role, since it transforms many constructs to
push_val instructions. That is, it tries to evaluate instructions
at compile time, and we refer to this process as caching.
This helps subsequent passes with
optimization since they can work with values that are known at compile time.
Some examples of what this pass does:
- Some global object lookups are cached. For example, it is usually
safe to cache lookups for
consoleorString. - Property lookups on some cached values are also cached. For example,
it is usually safe to cache the lookup of
logonconsole. this.foois cached iffoois a method in the same prototype as the method being compiled, and is not overridden in a super prototype.- … and more.
This pass makes heavy use of the “startup” JS context that was obtained earlier, since it needs to explore prototypes and objects from the user program.
InlinePass
InlinePass performs function inlining. Inlining is very important since
JS calls have overhead associated with them, and being
able to inline short methods (especially getters/setters) is a huge win.
Inlining also helps subsequent optimizations, since they are given much more
context to work with.
This pass is limited by how well CacheValuePass can cache values,
since otherwise, the pass cannot make any
assumptions about what methods are being called.
Typer
The Typer performs intraprocedural type inference, mostly to enable the
Lowering pass to make decisions about how instructions are lowered, but also
to determine whether values need to be reference counted. This improves
performance by
eliminating some type checks, and also helps alleviate the cost of reference
counting.
Configurable optimizations
Note that some of these optimizations (especially the CacheValuePass pass)
are overly optimistic and will not work in all scenarios.
To account for this, optimizations in
ChowJS are highly configurable. This is critical in an AOT context where
certain assumptions cannot be made without breaking semantics.
To make it more straightforward to configure optimizations, ChowJS can be compiled with checks enabled to determine if any assumptions are violated.
Fallbacks
While the IR is used to compile the vast majority of code, a fallback is
sometimes needed when features such as eval are used.
This means there are several tiers of execution:
- Bytecode: Bytecode running through an interpreter.
- Unoptimized machine code: Machine code generated directly from bytecode. This is done by inlining the opcode handler for each bytecode instruction, removing the opcode dispatch overhead. We also perform some limited peephole optimizations here. This is similar to how V8’s Sparkplug works.
- Optimized machine code: Bytecode → IR → machine code, as described earlier.
The unoptimized machine code runs about ~1.6x faster than the interpreter.
Performance
Here are some scene update timings for an intensive scene in the game,
measured on a handheld console. The update times were averaged over
50 frames, and we used V8 8.7.220.31 for our test:
- ChowJS (interpreter only):
43.40msper frame. - V8 (interpreter only):
35.81msper frame. - ChowJS:
11.10msper frame.
For this scene, this means:
- ChowJS is about 3.23x faster than the V8 interpreter.
- ChowJS is about 3.91x faster than the ChowJS bytecode interpreter.
- The ChowJS interpreter is only about 1.21x slower compared to the V8 interpreter.
In particular, this brings us from sub-30 FPS with V8 to 60 FPS
with ChowJS.
Mission accomplished!
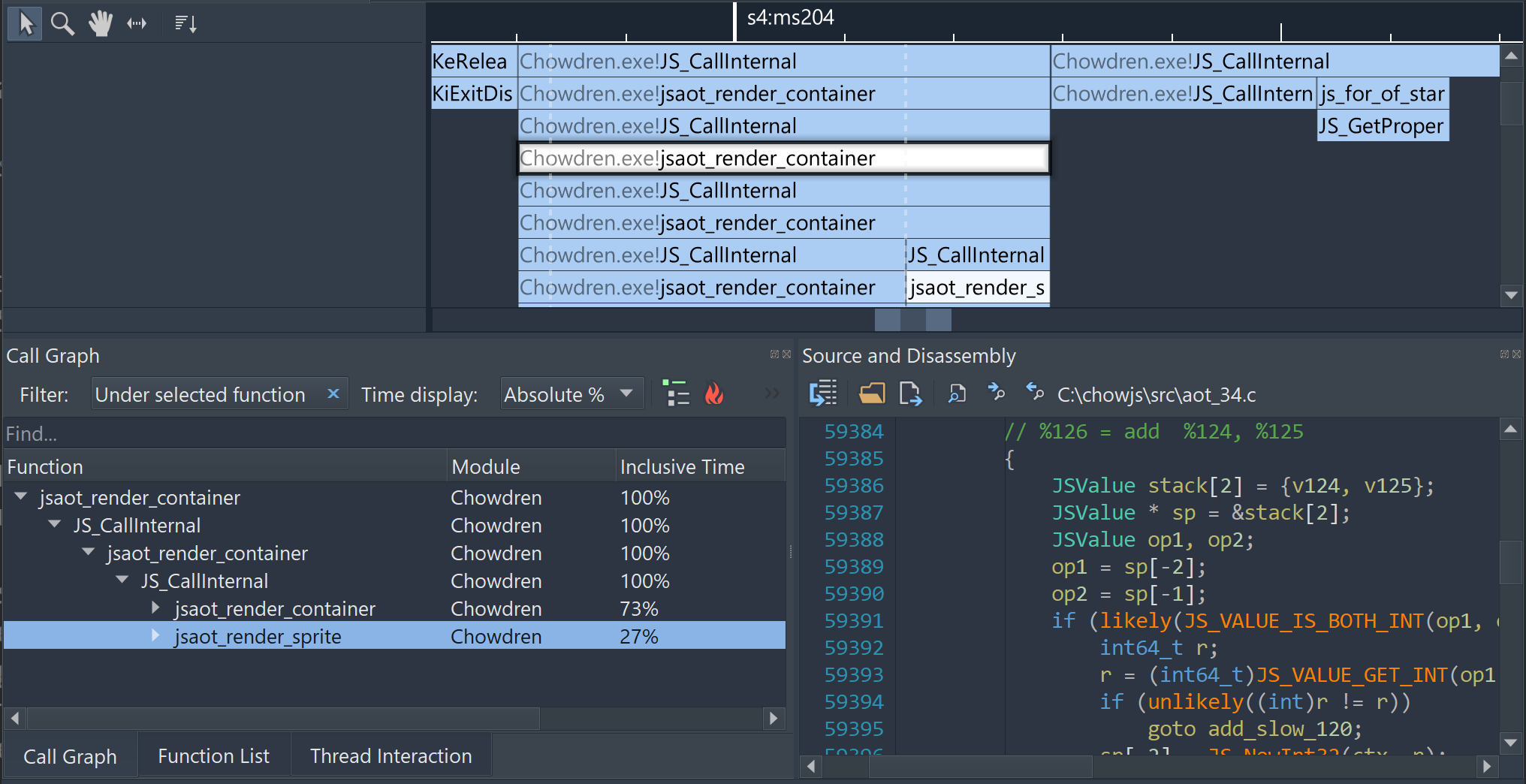
As an extra win, compiling JS methods to machine code makes it much more painless to profile JS applications using regular C/C++ tools. Here is a ChowJS executable being profiled by one of our favorite profilers, Superluminal:
Future
- Implementing a type of “profile-guided optimization” would benefit ChowJS a lot, and could allow us to make many more assumptions about types and object shapes that we cannot infer at compile time.
- ChowJS uses reference counting, and this was inherited from QuickJS. While we can remove many RC operations through optimization, there is still some overhead associated with RC compared to a high-throughput GC or a more sophisticated RC implementation.
- There are many opportunities for additional compiler optimizations, but for now, we are hitting our performance targets. We definitely expect to do even more with ChowJS in the future!
Get in touch
Are you making a commercial game in JavaScript, and are you looking to bring it to consoles? We’d love to talk!
You can get in touch at hi@mp2.dk.